Statistical Comparisons
Contents
Statistical Comparisons¶
Whenever we have data, we often want to use statistical analyses to explore, compare, and quantify our data.
In this notebook, we will briefly introduce and explore some common statistical tests that can be applied to data.
As with many of the topics in data analysis and machine learning, this tutorial is focused on introducing some related topics for data science, and demonstrated their application in Python, but it is out of scope of these tutorials to systematically introduce and describe the topic at hand, which in this case is statistics. If the topics here are unfamiliar, we recommend you follow the links or look for other resources to learn more about these topics.
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# Set random seed, for consistency simulating data
np.random.seed(21)
On Causality¶
Before we dive into particular statistical tests, just a general reminder that though we would often like to understand the causal structure of the data that we are interested in, this is generally not directly interpretable from statistical tests themselves.
In the follow, we will explore some statistical tests for investigating if and when distributions of data are the same or different, and if and how related they are. These tests, by themselves, do not tell us about what causes what. Correlation is not causation.
In the context of data science, this can be a limitation as we are often using previously collected datasets of convenience and observational datasets collected. Though we can explore the structure of the data, such datasets typically do not allow for causal interpretations.
Correlations¶
A common question we may be interested in is if two datasets, or two features of data, are related to each other.
If they, we would also like to now how related they are to each other.
For this, we can calculate correlations between features.
from scipy.stats import pearsonr, spearmanr
Simulate Data¶
First, let’s simulate some data.
For this example, we will simulate two arrays of data that do have a relationship to each other.
# Settings for simulated data
corr = 0.75
covs = [[1, corr], [corr, 1]]
means = [0, 0]
# Generate the data
d1, d2 = np.random.multivariate_normal(means, covs, 1000).T
Calculate Correlations¶
Next, we can calculate the correlation coefficient between our data arrays, using the pearsonr function from scipy.stats.
# Calculate a pearson correlation between two arrays of data
r_val, p_val = pearsonr(d1, d2)
print("The correlation coefficient is {:1.4f} with a p-value of {:1.2f}.".format(r_val, p_val))
The correlation coefficient is 0.7732 with a p-value of 0.00.
In this case, we have a high correlation coefficient, with a very low p-value.
This suggests our data are strongly correlated!
In this case, since we simulated the data, we know that this is a good estimation of the relationship between the data.
Rank Correlations¶
One thing to keep in mind is that the pearson correlation used above assumes that both data distributions are normally distributed.
These assumptions should also be tested in data to be analyzed.
Sometimes these assumptions will not be met. In that case, one option is to a different kind of correlation example. For example, the spearman correlation is a rank correlation that does not have the same assumptions as pearson.
# Calculate the spearman rank correlation between our data
r_val, p_val = spearmanr(d1, d2)
# Check the results of the spearman correlation
print("The correlation coefficient is {:1.4f} with a p-value of {:1.2f}.".format(r_val, p_val))
The correlation coefficient is 0.7595 with a p-value of 0.00.
In this case, the measured values for pearson and spearman correlations are about the same, since both are appropriate for the properties of this data.
T-Tests¶
Another question we might often want to ask about data is to check and detect when there is a significant difference between collections of data.
For example, we might want to analyze if there is a significant different in measured feature values between some groups of interest.
To do so, we can use t-tests.
There are different variants of t-test, including:
one sample t-test
test the mean of one group of data
independent samples t-test
test for a difference of means between two independent samples of data
related samples t-test
test for a difference of means between two related samples of data
For this example, we will explore using the independent samples t-test.
Functions for the other versions are also available in scipy.stats.
from scipy.stats import ttest_ind
Simulate Data¶
First, let’s simulate some data.
For this example, we will simulate two samples of normally distributed data.
# Settings for data simulation
n_samples = 250
# Simulate some data
d1 = norm.rvs(loc=0.5, scale=1, size=n_samples)
d2 = norm.rvs(loc=0.75, scale=1, size=n_samples)
# Visualize our data comparison
plt.hist(d1, alpha=0.5, label='D1');
plt.axvline(np.mean(d1), linestyle='--', linewidth=2, color='blue')
plt.hist(d2, alpha=0.5, label='D2');
plt.axvline(np.mean(d2), linestyle='--', linewidth=2, color='orange')
plt.legend();
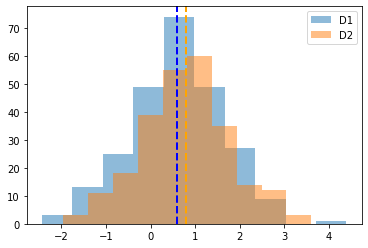
Calculate T-Tests¶
Now that we have some data, let’s use a t-tests to statistically compare the two groups of data.
For this example, we will test whether the two distributions have significantly different means.
# Run independent samples t-test
t_val, p_val = ttest_ind(d1, d2)
# Check the results of the t-test
print('T-Test comparison of D1 & D2:')
print('\tT-value \t {:1.4f}'.format(t_val))
print('\tP-value \t {:1.2e}'.format(p_val))
T-Test comparison of D1 & D2:
T-value -2.2502
P-value 2.49e-02
In this case, the t-test shows that there is a significant difference in the mean of the two arrays of data!
Assumptions of T-Tests¶
Note, again, that t-tests assume normally distributed data. This is again a property of the data that should be examined before applying statistical tests. If this assumption is not met, other approaches for comparing the data may be needed.
Effect Size¶
One thing to keep in mind about hypothesis tests such as the t-test above is that they while they can be used to is there a difference between two sets of data, they do not answer the question of how different are they.
Often, we would also like to measure how different groups of data are.
To do so, we can use effect size measures, which can be used to estimate the magnitude of changes or differences.
There are many methods and approaches to measuring effect sizes across different contexts.
For this example, we will use cohens-d effect size estimate for differences in means.
Defining Effect Size Code¶
Often, when analyzing data, we will want to apply some measure that we may not find already available, in which case we may need to implement a version ourselves.
For this example, we will implement cohens-d, an effect size measure for differences of means. Briefly, is a calculation of the difference of means between two distributions, divided by the pooled standard deviation. As such, cohens-d is a standardized measure, meaning the output value is independent of the units of the inputs.
Note that math and statistics are standard library modules that contain some useful basic numerical functionality.
from math import sqrt
from statistics import mean, stdev
def compute_cohens_d(data_1, data_2):
"""Compute cohens-d effect size.
Parameters
----------
data_1, data_2 : 1d array
Array of data to compute the effect size between.
Returns
-------
cohens_d : float
The computed effect size measure.
"""
# Calculate group means
d1_mean = mean(data_1)
d2_mean = mean(data_2)
# Calculate group standard deviations
d1_std = stdev(data_1)
d2_std = stdev(data_2)
# Calculate the pooled standard deviation
pooled_std = sqrt((d1_std ** 2 + d2_std ** 2) / 2)
# Calculate cohens-d
cohens_d = (d1_mean - d2_mean) / pooled_std
return cohens_d
# Calculate the cohens-d effect size for our simulated data from before
cohens_d = compute_cohens_d(d2, d1)
# Check the measured value of the effect size
print('The cohens-d effect size is {:1.2f}.'.format(cohens_d))
The cohens-d effect size is 0.20.
A cohens-d effect size of ~0.2 is a small or modest effect.
In combination with our t-test above, we can conclude that there is a difference of means between the two groups of data, but that the magnitude of this difference is relatively small.
Conclusion¶
Here we have briefly explored some statistical tests and comparisons for numerical data.
For more information on statistical tests of data, check out courses and resources focused on statistics.