Linear Models
Contents
Linear Models¶
Linear Models - Overview¶
In the simplest case, we are trying to fit a line. In this case, our model is of the form:
In this equation above, we are trying to predict some data variable \(y\), from some other data variable \(x\), where \(a\) and \(b\) are parameters we need to figure out (learn), by fitting the model, and reflect the slope, and y-intercept, of the model (line) respectively.
We need some procedure to go about finding \(a\) and \(b\). We will use OLS to do so - the values of \(a\) and \(b\) we want are those that fulfill the OLS solution - meaning the values that lead to the smallest distance between the predictions of the model, and our data.
Note that to train this kind of model, you need data in which you know both \(x\) and \(y\) already, to train your model. This kind of model only applies to predicting values you have at least some information about.
Having training data makes it a ‘supervised’ model, meaning that learning the prediction model is ‘supervised’ or guided by knowing some ‘answers’ to our prediction problem already, and the goal is to use this data to learn a model that can generalize to new data.
This approach can also be generalized, including, for example, more features used to predict our output of interest.
Therefore, we will rewrite our model, in the general form, as:
In the equation above \(a_0\) is the intercept (the same as \(b\) from above), and \(a_1\) to \(a_n\) are \(n\) parameters that we are trying to learn, as weights for data features \(x_1\) to \(x_n\). Our output variable (what we are trying to predict) is still \(y\), and we’ve introduced \(\epsilon\), which is the error, which basically captures unexplained variance.
Linear Models Practice¶
In the following, we will generate some data, with two features, that we’ll call d1 and d2.
We will generate this data such that d1 and d2 are correlated. This means that they share some information, and so we can use this to property to try and predict values of d2 from d1, using a linear model to do so.
This model, using the second notation from above, will be of the form:
Where a_0 and a_1 are parameters of the model that we are trying to learn, reflecting the intercept and slope, respectively.
# Imports
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Statmodels & patsy
import patsy
import statsmodels.api as sm
First, lets generate some example data to use.
# Set random seed, for consistency simulating data
np.random.seed(21)
# Settings
corr = 0.75
covs = [[1, corr], [corr, 1]]
means = [0, 0]
# Generate the data
data = np.random.multivariate_normal(means, covs, 1000)
# Check out the data we generated
plt.scatter(data[:, 0], data[:, 1], alpha=0.5);
# Put the data into a DataFrame
df = pd.DataFrame(data, columns=['d1', 'd2'])
# Have a quick look at the simualed data
df.head()
| d1 | d2 | |
|---|---|---|
| 0 | 0.087922 | 0.009294 |
| 1 | -0.530187 | -1.418836 |
| 2 | -0.092297 | -1.302195 |
| 3 | 0.275502 | 0.109635 |
| 4 | -1.050818 | -1.059746 |
# Check the correlation between d1 & d2 (that it matches what was synthesized)
df.corr()
| d1 | d2 | |
|---|---|---|
| d1 | 1.000000 | 0.773245 |
| d2 | 0.773245 | 1.000000 |
Linear Models with Statsmodels & Patsy¶
Patsy gives us an easy way to construct ‘design matrices’.
For our purpose, ‘design matrices’ are just organized matrices of our predictor and output variables.
‘Predictors’ refers to the features we want to predict from, and ‘outputs’ refers to the variables we want to predict.
# Use patsy to organize our data into predictor and outputs
# The string `d2 ~ d1` indicates to predict d2 as a function of d1
outcome, predictors = patsy.dmatrices('d2 ~ d1', df)
If you check the type of ‘outcome’ and ‘predictors’, you will find they are custom patsy objects, of type ‘DesignMatrix’.
If you print them out, you will see that they resemble pandas Series or DataFrames.
You can think of them as customized dataframe-like objects for the specific purpose of being organized into matrices to be used for modeling.
Next, we can use statsmodels to initialize an OLS model object.
# Initialize an OLS model object
# Note: This initializes the model, and provides the data
# but does not actually compute the model yet
model = sm.OLS(outcome, predictors)
Note that statsmodels, just like sklearn that we will encounter a bit later, uses an object-oriented approach.
In this approach you initialize objects that store the data and methods together. This allows for an organized approach to storing and check data and parameters, and applying computations to them, such as fitting models. Outputs parameters of the model are also stored in the object, which can then also be used to make predictions.
# Check the type of the model object we just created.
# You can also explore, with tab-complete, what is available from this object
type(model)
statsmodels.regression.linear_model.OLS
# Finally, fit the model
results = model.fit()
# Check out the results
print(results.summary())
OLS Regression Results
==============================================================================
Dep. Variable: d2 R-squared: 0.598
Model: OLS Adj. R-squared: 0.598
Method: Least Squares F-statistic: 1484.
Date: Sun, 21 Jun 2020 Prob (F-statistic): 1.18e-199
Time: 16:14:06 Log-Likelihood: -953.74
No. Observations: 1000 AIC: 1911.
Df Residuals: 998 BIC: 1921.
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -0.0116 0.020 -0.582 0.561 -0.051 0.027
d1 0.7396 0.019 38.523 0.000 0.702 0.777
==============================================================================
Omnibus: 0.715 Durbin-Watson: 2.008
Prob(Omnibus): 0.699 Jarque-Bera (JB): 0.787
Skew: -0.014 Prob(JB): 0.675
Kurtosis: 2.866 Cond. No. 1.04
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Interpreting Outputs¶
statsmodels gives us a lot of information!
The top section is largely meta-data: it includes things like the model type, and time and date of us running it.
It also includes the R-squared, which is an overall summary of the amount of variance the model is able to capture. R-squared values are bound between 0-1. An r-squared of ~0.5, that we have here, is quite a high value, suggesting a good model fit.
The middle section is the actual model results.
Each row reflects a parameter, and gives us it’s value (coef), the error (std err), the results of a statistical test regarding whether this parameter is a significant predictor of the output variable (t, which associated p-value as P>|t|), and the confidence interval of the parameters value ([0.025 - 0.975]).
The last section includes some other tests that are run on the data. These can be used to check some properties of the input data, and to check assumptions of the model are met.
Checking our Model¶
In terms of the model itself, the most useful components are in the second row, in which the summary gives the parameter values, and p-values of our predictors, which in this case are ‘Intercept’, and ‘d2’.
From the results above, we can grab the values of the parameters, and obtain the following model:
However, we should also keep in mind whether each parameter is significant. To check use, let’s look at the statistical test that is reported that checks whether the parameter value is significant (as in, significantly different from zero). Using an alpha value of 0.05, in this case, the ‘d2’ parameter value is significant, but the ‘Intercept’ value is not. Since the parameter value for ‘Intercept’ is not significantly different from zero, we can decide not to include it in our final model.
We therefore finish with the model: $\( d2 = 0.7396 * d1 \)$
With this model, it is promising that are value of \(a_1\), of 0.7396, is very close to the correlation value of the data points, which we set at 0.75! This suggest our model is working well!
Visualizing our Model¶
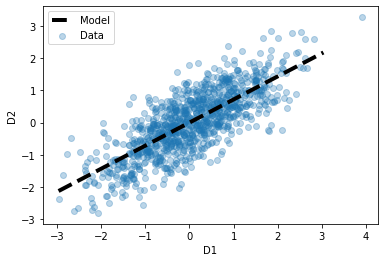
Next, we can visualize our model, with our data.
# Plot the orginal data (as before)
plt.scatter(df['d1'], df['d2'], alpha=0.3, label='Data');
# Generate and plot the model fit line
xs = np.arange(df['d1'].min(), df['d1'].max())
ys = 0.7185 * xs
plt.plot(xs, ys, '--k', linewidth=4, label='Model')
plt.xlabel('D1')
plt.ylabel('D2')
plt.legend();
Using multiple predictors¶
The model above used only one predictor, fitting a straight line to the data. This is similar to previous examples we’ve seen of and tried for fitting lines.
We can also fit more than 1 predictor variable, and that is where the power and benefits of using patsy and statsmodels really comes through. We can use these tools to specify any models we want, including multiple predictors with different kinds of interactions between predictors, and these functions take care of fitting these models.
To briefly explore this, let’s now add a new variable to our dataframe, and fit an OLS model with two predictors.
In this case, we will fit a model of the form:
# Add a new column of data to df
df['d3'] = pd.Series(np.random.randn(1000), index=df.index)
df.head()
| d1 | d2 | d3 | |
|---|---|---|---|
| 0 | 0.087922 | 0.009294 | -1.611758 |
| 1 | -0.530187 | -1.418836 | 1.933703 |
| 2 | -0.092297 | -1.302195 | 0.334072 |
| 3 | 0.275502 | 0.109635 | -0.124464 |
| 4 | -1.050818 | -1.059746 | 0.278050 |
# Predict d1 from d2 and d3
outcome, predictors = patsy.dmatrices('d1 ~ d2 + d3', df)
model = sm.OLS(outcome, predictors)
results = model.fit()
# Check the model fit summary
print(results.summary())
OLS Regression Results
==============================================================================
Dep. Variable: d1 R-squared: 0.599
Model: OLS Adj. R-squared: 0.598
Method: Least Squares F-statistic: 745.1
Date: Sun, 21 Jun 2020 Prob (F-statistic): 1.21e-198
Time: 16:14:06 Log-Likelihood: -996.62
No. Observations: 1000 AIC: 1999.
Df Residuals: 997 BIC: 2014.
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 0.0179 0.021 0.861 0.389 -0.023 0.059
d2 0.8070 0.021 38.471 0.000 0.766 0.848
d3 -0.0368 0.021 -1.763 0.078 -0.078 0.004
==============================================================================
Omnibus: 0.703 Durbin-Watson: 1.985
Prob(Omnibus): 0.704 Jarque-Bera (JB): 0.574
Skew: 0.015 Prob(JB): 0.751
Kurtosis: 3.113 Cond. No. 1.06
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Note that in this case, we simulated the d3 column with no relation to the d1 values we were trying to predict, so the d3 predictor isn’t significant, and overall this bigger model doesn’t explain anymore variance of the data (the r-squared is no better).
Conclusion¶
statsmodels offers a powerful and general approach to fitting statistical models to data, investigating properties of these model fits, and comparing between models. You can further investigate how to include other features, such as interactions between input variables, and so on.
Linear Regression with sklearn¶
As we’ve already seen with the OLS tutorial, there are multiple ways to apply the same underlying computations.
Another popular module that can be used for fitting models to data is sklearn.
Here, for a quick demonstration and comparison, we will fit the sklearn implementation of Linear Regression models to our same data. The underlying computations are approximately the same, but as we can see, the API for using sklearn and the exact results are different.
# Linear Models with sklearn
from sklearn import linear_model
# Convert data into arrays for easier use with sklearn
d1 = np.reshape(df.d1.values, [len(df.d1), 1])
d2 = np.reshape(df.d2.values, [len(df.d2), 1])
d3 = np.reshape(df.d3.values, [len(df.d3), 1])
# Initialize linear regression model
reg = linear_model.LinearRegression()
# Fit the linear regression model
reg.fit(d2, d1) # d1 = a0 + a1*d2
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
# Check the results of this
# If you compare these to what we got with statsmodels above, they are indeed the same
print('The intercept value is: \t{:1.4f}'.format(reg.intercept_[0]))
print('The coefficient value is: \t{:1.4f}'.format(reg.coef_[0][0]))
The intercept value is: 0.0164
The coefficient value is: 0.8084
Using multiple predictors (in sklearn)¶
# Initialize and fit linear model
# d1 = a0 + a1*d2 + a2*d3
reg = linear_model.LinearRegression()
reg.fit(np.hstack([d2, d3]), d1)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
# Check the results of this
# If you compare these to what we got with statsmodels above, they are indeed the same
print('Intercept: \t {:+1.4f}'.format(reg.intercept_[0]))
print('d2 value:\t {:+1.4f}'.format(reg.coef_[0][0]))
print('d2 value:\t {:+1.4f}'.format(reg.coef_[0][1]))
Intercept: +0.0179
d2 value: +0.8070
d2 value: -0.0368
Conclusion¶
The pattern of results with sklearn is about the same as before, though we can see there is some small differences in estimation. In general, if you have data organized into Dataframes, then statsmodels does offer a more direct way to apply statistical models, but sklearn does also offer a lot of useful functionality for model fitting & analysis.