Clustering
Contents
Clustering¶
A common task or goal within data analysis is to learn some kind of structure from data. One way to do so is to apply clustering analysis to data. This typically means trying to learn ‘groups’ or clusters in the data.
This example is a minimal example of clustering adapted from the sklearn tutorials, to introduce the key points and show an introductory example of a clustering analysis.
As with many of the other topics in data analysis, there are many resources and tutorials available on the clustering analyses. A good place to start is the extensive coverage in the sklearn documentation. If you are interested in clustering analyses, once you have explored the basic concepts here, we recommend you go and explore some of these other resources.
# Imports
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from sklearn import cluster, datasets
from sklearn.cluster import KMeans
from scipy.cluster.vq import whiten
Load an Example Dataset¶
Scikit-learn has example datasets that can be loaded and used for example.
Here, we’ll use the iris dataset. This dataset contains data about different species of plants. It includes information for several features across several species. Our task will be to attempt to cluster the data, to see if we can learn a meaningful groupings from the data.
# Load the iris data
iris = datasets.load_iris()
Note that iris, as loaded by sklearn is an object. The data is stored in iris.data.
# Let's check how much data there is
[n_samples, n_features] = np.shape(iris.data)
n_labels = len(set(iris.target))
print("There are {} samples of data, with {} features and {} labels.".format(\
n_samples, n_features, n_labels))
There are 150 samples of data, with 4 features and 3 labels.
# Check out the available features
print('\n'.join(iris.feature_names))
sepal length (cm)
sepal width (cm)
petal length (cm)
petal width (cm)
# Check out the species ('clusters')
print('\n'.join(iris.target_names))
setosa
versicolor
virginica
# Let's set up some indexes, so we know what data we're using
sl_ind = 0 # Sepal Length
sw_ind = 1 # Septal Width
pl_ind = 2 # Petal Length
pw_ind = 3 # Petal Width
# Let's start looking at some data - plotting petal length vs. petal width
plt.scatter(iris.data[:, pl_ind], iris.data[:, pw_ind])
# Add title and labels
plt.title('Iris Data: Petal Length vs. Width', fontsize=16, fontweight='bold')
plt.xlabel('Petal Length (cm)', fontsize=14);
plt.ylabel('Petal Width (cm)', fontsize=14);
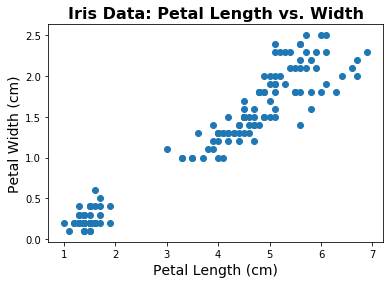
Just from plotting the data, we can see that there seems to be some kind of structure in the data.
In this case, we do know that there are different species in our dataset, which will be useful information for comparing to our clustering analysis.
Note that we are not going to use these labels in the clustering analysis itself. Clustering, as we will apply it here, is an unsupervised method, meaning we are not going to use any labels to try and learn the structure of the data.
To see the structure that is present in the data, let’s replot the data, color coding by species.
# Plot the data color coded by species
for ind in range(n_labels):
plt.scatter(iris.data[:, pl_ind][iris.target==ind],
iris.data[:, pw_ind][iris.target==ind],
label=iris.target_names[ind])
# Add title, labels and legend
plt.title('Iris Data: Petal Length vs. Width', fontsize=16, fontweight='bold')
plt.xlabel('Petal Length (cm)', fontsize=14);
plt.ylabel('Petal Width (cm)', fontsize=14);
plt.legend(scatterpoints=1, loc='upper left');
# Note that the data, colored by label, can also be plotted like this:
# plt.scatter(iris.data[:, pl_ind], iris.data[:, pw_ind], c=iris.target)
# It is, however, more difficult to add labelled legend when plotted this way
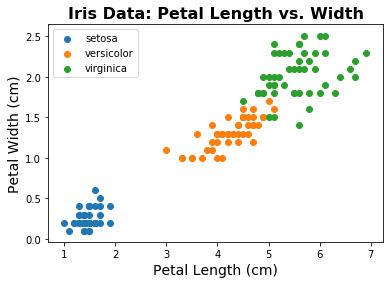
In this data, we know we have 3 different ‘groups’ of data, which are the different species.
As we can see in the plots above, these different species seem to be fairly distinct in terms of their feature values.
The question then is whether we can learn a clustering approach, based on the feature data and without using the labels, that can learn a meaningful grouping of this data.
If this approach works, then we might be able to try to use it on other data, for which we have feature data, but might not be sure about the groupings present in the data.
Apply K-Means Clustering¶
Clustering is the process of trying to learn groups algorithmically.
For this example, we are going to use the K-means clustering algorithm.
K-means attempts to group the data into k clusters, and does so by labeling each data point to be in the cluster with the nearest mean. To learn the center means, after a random initialization, an iterative procedure assigns each point to a cluster, then updates the cluster centers, and repeats, until a final solution is reached.
# Pull out the data of interest - Petal Length & Petal Width
d1 = np.array(iris.data[:, pl_ind])
d2 = np.array(iris.data[:, pw_ind])
Whitening Data¶
In this example, we are using two features (or two dimensions) of data.
One thing to keep in mind for clustering analyses, is that if different dimensions use different units (or have very different variances), then these differences can greatly impact the clustering.
This is because K-means is isotropic, which means that it treats different in each direction as equally important. Because of this, if the units or variance of different features are very different, this is equivalent to weighting certain features / dimensions as more or less important.
To correct for this it is common, and sometimes necessary to ‘whiten’ the data. ‘Whitening’ data means normalizing each dimension by it’s respective standard deviation. By transforming the data to be on the same scale (have the same variance), we can ensure that the clustering algorithm treats each dimension with the same importance.
# Check out the whiten function
whiten?
# Whiten Data
d1w = whiten(d1)
d2w = whiten(d2)
# Combine data into an array to use with sklearn
data = np.vstack([d1w, d2w]).T
# Initialize K-means object, and set it to fit 3 clusters
km = KMeans(n_clusters=3, random_state=13)
# Fit the data with K-means
km.fit(data)
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=3, n_init=10, n_jobs=None, precompute_distances='auto',
random_state=13, tol=0.0001, verbose=0)
# Let's check out the clusters that KMeans found
plt.scatter(d1, d2, c=km.labels_);
# Add title, labels and legend
plt.title('Iris Data: PL vs. PW Clustered', fontsize=16, fontweight='bold')
plt.xlabel('Petal Length (cm)', fontsize=14);
plt.ylabel('Petal Width (cm)', fontsize=14);
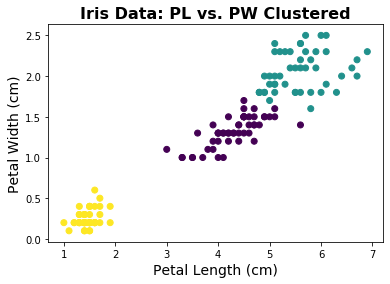
In the plot above, each data point is labeled with it’s cluster assignment, that we learned from the data.
In this case, since we do already know the species label of the data, we can see that it seems like this clustering analysis is doing pretty well! There are some discrepancies, but overall a K-means clustering approach is able to reconstruct a grouping of the datapoints, using only information from a couple of the features.
Other Clustering Approaches¶
Clustering is a general task, and there are many different algorithms that can be used to attempt to solve it.
For example, below are printed some of the different clustering algorithms and approaches that are available in sklearn.
print('Clustering approaches in sklearn:')
for name in dir(cluster):
if name[0].isupper():
print(' ', name)
Clustering approaches in sklearn:
AffinityPropagation
AgglomerativeClustering
Birch
DBSCAN
FeatureAgglomeration
KMeans
MeanShift
MiniBatchKMeans
OPTICS
SpectralBiclustering
SpectralClustering
SpectralCoclustering